
The Hype is Ripe: Objective LLM Evals

This post is inspired by a LinkedIn chat with Li Yin, who’s building this open-source project for LLM evaluation. Most “AI” companies in 2024 will go down if GCP Vertex, OpenAI and Anthropic all go down simultaneously. More importantly, what happens to your company when the vendor you went all-in on goes down or gets obsoleted?
The landscape is rapidly shifting as the "Big 3" regularly leapfrog each other in terms of performance with new models. The upcoming release of GPT-o1 and subsequent models will only add to the volatility of the landscape. Many companies are trying to implement AI solutions without clear use cases, risk evaluation, or any plans for insuring against system failures or hallucinations.
Shameless self-promotion plug: it’s a problem I had, so I built a company to solve it.
Target Audience
If your company or engineering team is implementing your own foundational or fine-tuned models, this post will be be as breaking news as the sky being blue. However, if your organization is considering external vendors, APIs, or things like GPT/Anthropic Enterprise, grab a cup of coffee and read on for I hope this shall be useful to you.
Evaluating vendors is critical. You test a vendor like Salesforce or HubSpot, assess its performance for your company or organization, and then decide whether to sign a contract. But how do you properly evaluate the pros and cons of an AI vendor?
Step 1) have concrete business use cases and projected GMV value gains from them.
Step 2) have outage contingencies - both technically and operationally. Consider risk.
Step 3) What this post is about: evaluate the system at hand for quality and reliability.
Initial Evaluation
Let’s cover some great resources for foundational model evaluation and how we can apply them to effectively evaluate more complex, hybrid systems that include multiple models, data sources, and methods of retrieval and operation (e.g., RAG, graph, etc.).
If you care, but not enough to do evals, HF’s leaderboard is your new best friend.
PromptBench is a great wide-sweep starting point and has its’ own technical report:

If you are new to “the game”, try it first. It may not be the best and most feature-rich eval but it is comprehensive and encourages review of the whole end to end process.
Next up, the big fish: OpenAI Evals and Anthropic’s excellent overview of the process:
Honorary Mentions:
Confident AI’s kindly open sourced DeepEval is the quickest and simplest way to find out the industry-wide benchmarks like MMLU, HumanEval, and GSM8K.
Then we have Amazon’s FMEval with its’ complimentary and informative guide.
And the inspiration for this post, AdalFlow plus its’ guide and notebook.
These resources should provide an ENG team with a good starting point in ML. After baseline evaluations, the next steps are augmented and runtime evaluations, which yield actionable advice on areas for improvement to take things up a notch. This absolute gem of an illustration by Eduardo Ordax is a well-balanced overview:

As we venture into optimization, ongoing evaluation via the above is your key metric.
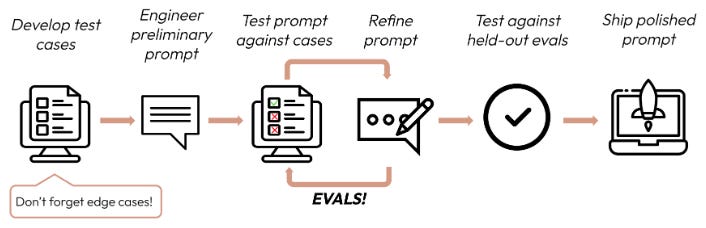
Prompt Engineering
Brace yourself for the horror of our Miro diagrams because I am no graphic designer. Let’s start with the basics of how you (probably) want to manage / monitor prompts:

RAG
Usually bottom hanging fruit, it’s easy to get it wrong but stuff like Attention Maps is helpful, and hybrid RAG wins. RAG is everywhere so I’m not going to waste your time regurgitating content about it. The only not obvious thing I can think of is MLT RAG. Most of this is via Big 3 cloud infra anyways - easy ways to start: GCP Vertex and GAS.
Fine-Tuning
Also easy to get it wrong. I am personally a fan of this method called MoRA for very cost and time effective fine-tuning. Fine-tuning is also beat to death, my advice is to not reinvent the wheel and use a vendor that’s good at it. Some notable ones are:
Comet ML is basically the big fish …my company is quickly migrating to it.
Together AI was our starter. The combo of training & inference is great.
Battle tested: Weights and Biases
Up and coming: Valohai
For the Unhinged
Arguably not fine-tuning, here’s an underrated hipster approach along with its paper. If all else fails or you just want to play on hard mode, you can try directly editing your model. Aight, time to wrap this rant: if you’re having 99k context length problems (GitHub) I feel bad for you son, because graph traversal (mostly) ain’t got none.
