
Dev From Scratch: 4/n
Effective AI-assisted development using only local resources

Chapter 4 of “development from scratch”, where we build a competitive and highly effective AI-assisted coding environment using only local models and resources.
This chapter covers optimizing a general-purpose Qwen3 model to run at 150+ TPS.
Link to previous chapter | Link to next chapter | Link to companion GitHub repo
The following clip, which you’ll replicate in this post, is in real-time and not sped up:
Benchmarking
Unoptimized
# Install aiperf
pipx install aiperf
# Start with previous unoptimized vLLM in a separate terminal window
"$(git root)/docs/002_inference/run-model.sh"
# Warm up vLLM
curl http://localhost:1337/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "nvidia/Qwen3-30B-A3B-NVFP4",
"messages": [{"role": "user", "content": "hi"}],
"max_tokens": 10
}'
# Run a basic perf test
aiperf profile \
--url http://localhost:1337 \
--model "nvidia/Qwen3-30B-A3B-NVFP4" \
--endpoint-type chat \
--streaming \
--concurrency 1 \
--num-requests 10If running on similar hardware to that in Chapter 1, you should see something like:
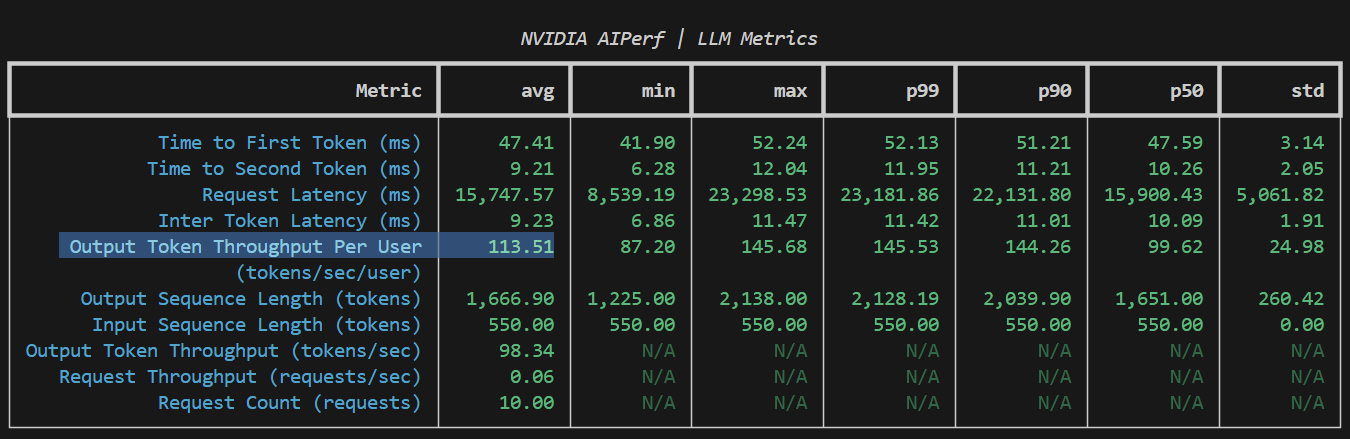
Now stop the vLLM container. 113.51 TPS is already faster than a Vertex, Bedrock, OpenAI or GitHub Copilot API. But why stop here? Let’s do some sketchy stuff.
Let’s Get Weird
Pull down the latest version of the GitHub repo if you’ve been following along.
What’s better than pulling sus nightly builds? Nothing. Nothing could be better. If that wasn’t enough, there’s even a /sed/ patch …in the Dockerfile. We’re living the wild life.
# Build container from sketchy nightly wheels and shady locker room trolls
# chmod +x "$(git root)/docs/003_optimization/build.sh"
# "$(git root)/docs/003_optimization/build.sh"
# Run with newly added optimizations in a separate terminal window
chmod +x "$(git root)/docs/003_optimization/run-model.sh"
"$(git root)/docs/003_optimization/run-model.sh"
# Warm up vLLM
curl http://localhost:1337/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer EMPTY" \
-d '{
"model": "nvidia/Qwen3-30B-A3B-NVFP4",
"messages": [{"role": "user", "content": "hi"}],
"max_tokens": 10
}'
# Run the same perf test
aiperf profile \
--url http://localhost:1337 \
--model "nvidia/Qwen3-30B-A3B-NVFP4" \
--endpoint-type chat \
--streaming \
--concurrency 1 \
--num-requests 10You should see ~172TPS, a roughly 51% increase. Spin up the UI and try how fast it is:
"$(git root)/docs/002_inference/run-ui.sh"Link to local UI. This is where “Effective AI-assisted development using local resources” is going: Modern LMs are plenty capable and this is notably faster than API calls.
Most folks don’t fully appreciate how heavily they’re guilty of model overkill. With the right setup you’ll have LM code assist that works ~90% as well but is 400-700% faster.
Next up: Setting up coding-specialized models and connecting them to VS Code.